🤖 에이전트와 환경의 상호작용

강화학습은 에이전트(Agent)와 환경(Environment)의 반복적인 상호작용을 통해 이루어진다.
- 시간
t일 때, 환경은 에이전트에게 현재 상태S_t를 제공한다. - 에이전트는 이 상태 정보를 바탕으로 가능한 행동 집합
{a1, a2, a3, a4}중 하나인A_t를 선택하고 행동한다. - 환경은 이 행동에 대한 평가로 보상
r_{t+1}을 전달하고, 새로운 상태S_{t+1}을 알려준다.
🎯 에이전트는 이렇게 받은 보상을 최대화하기 위해, 앞으로 받을 보상의 합 G가 가장 크게 되는 최적 정책(π*)을 학습하게 된다.
🧱 미로 환경 정의
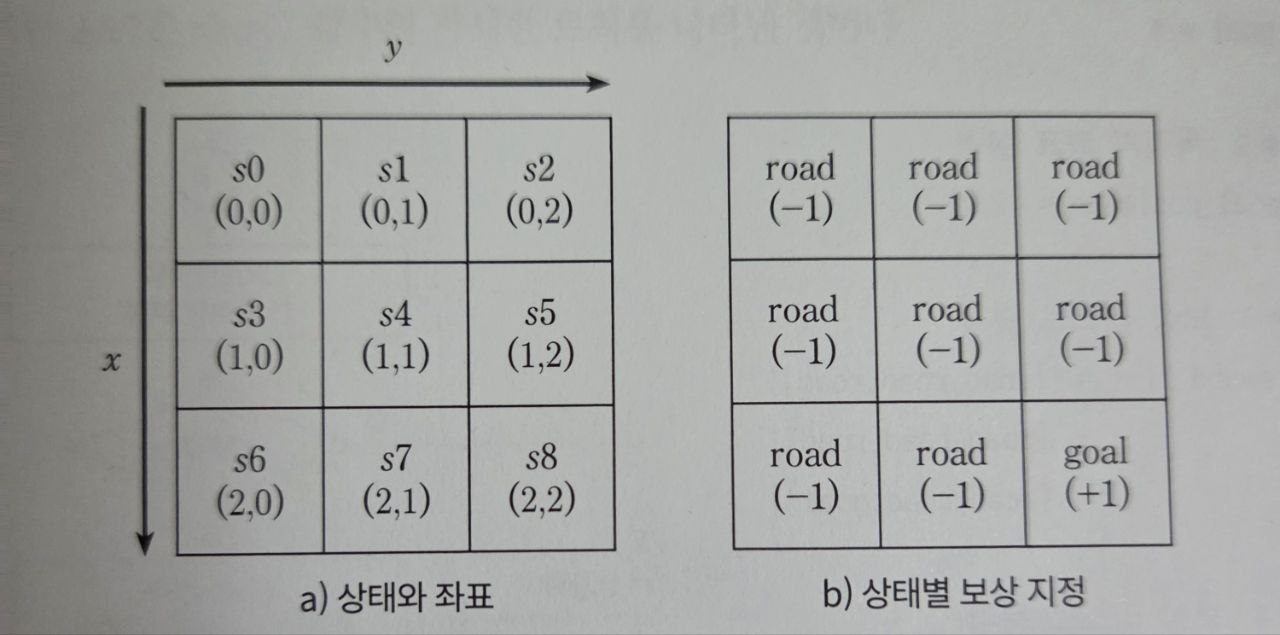
▶ 상태 구성
3×3 형태의 미로 환경은 다음과 같은 좌표로 정의된다.
s0(0,0) s1(0,1) s2(0,2)
s3(1,0) s4(1,1) s5(1,2)
s6(2,0) s7(2,1) s8(2,2) - 세로를 x축, 가로를 y축으로 정의
- 시작 지점: (0,0) / 도착 지점: (2,2)
▶ 보상 테이블
에이전트가 도달한 위치에 따라 보상이 다르게 설정된다.
| 상태 | 보상 |
|---|---|
road |
-1 |
goal |
+1 |
| 미로 밖 | -3 |
🧩 Environment 클래스
class Environment:
# 1. 미로 밖(절벽), 길, 목적지와 보상 설정
cliff = -3
road = -1
goal = 1
# 2. 목적지 좌표 설정
goal_position = [2,2]
# 3. 보상 리스트 숫자
reward_list = [[road, road, road],
[road, road, road],
[road, road, goal]]
# 4. 보상 리스트 문자
reward_list1 = [["road", "road", "road"],
["road", "road", "road"],
["road", "road", "goal"]]
# 5. 보상 리스트를 array로 설정
def __init__(self):
self.reward = np.asarray(self.reward_list)reward_list: 숫자로 구성된 보상값 배열reward_list1: 상태 이름을 문자열로 표현
🔄 move() 함수 정의
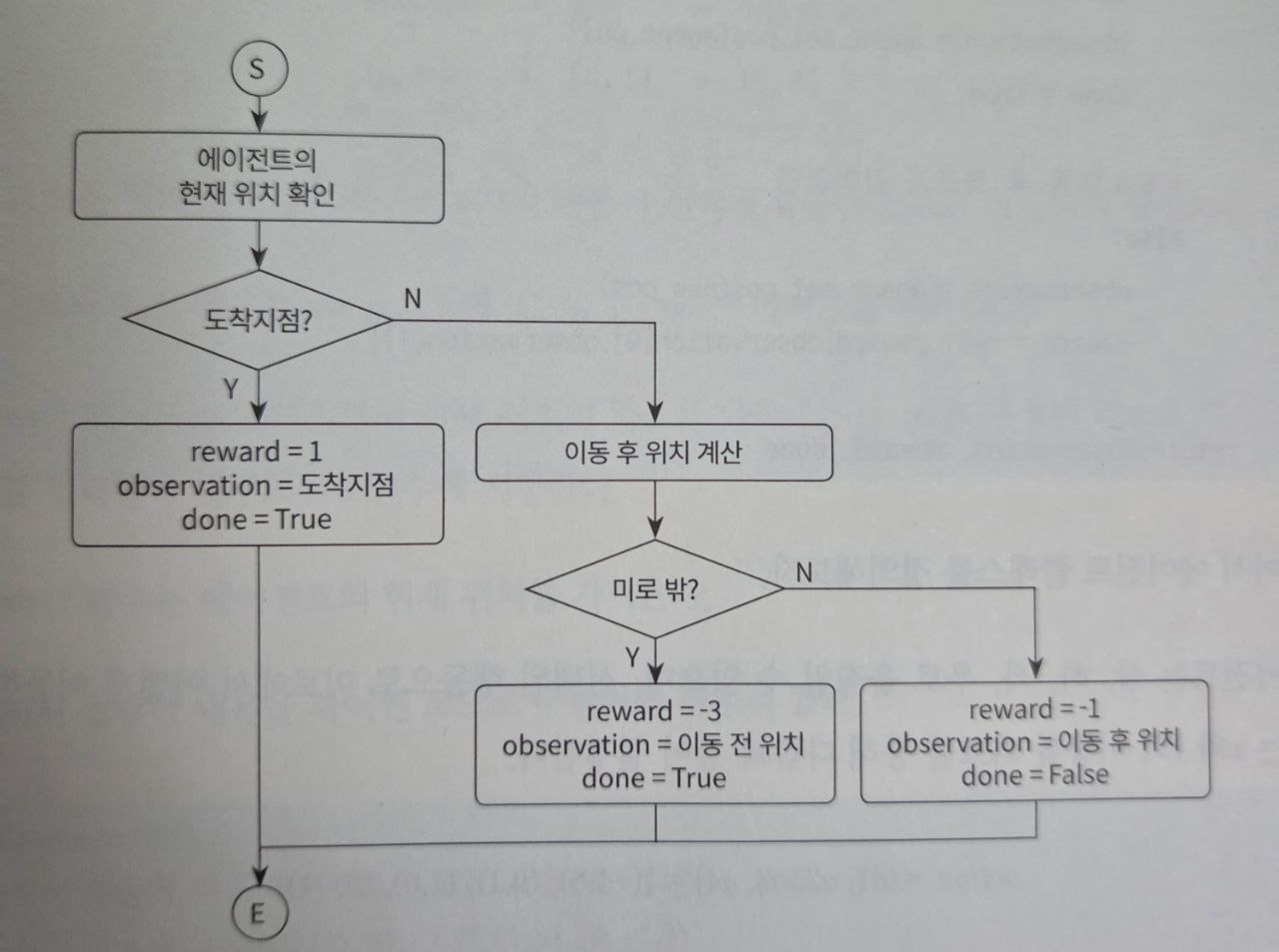
에이전트의 행동 결과를 바탕으로 보상과 다음 상태를 반환한다.
# 6. 선택된 에이전트의 행동 결과 반환(미로 밖일 경우 이전 좌표로 다시 복귀)
def move(self, agent, action):
done = False
# 6.1 행동에 따른 좌표 구하기
# 현재 좌표: agent.pos
# 이동 후 좌표: new_pos
new_pos = agent.pos + agent.action[action]
# 6.2 현재 좌표가 목적지인지 확인
if self.reward_list1[agent.pos[0]][agent.pos[1]] == "goal":
reward = self.goal
observation = agent.set_pos(agent.pos)
done = True
# 6.3 이동 후 좌표가 미로 밖인지 확인
elif new_pos[0] < 0 or new_pos[0] >= self.reward.shape[0] \
or new_pos[1] < 0 or new_pos[1] >= self.reward.shape[1]:
reward = self.cliff
observation = agent.set_pos(agent.pos)
done = True
# 6.4 이동 후 좌표가 길이라면
else:
observation = agent.set_pos(new_pos)
reward = self.reward[observation[0], observation[1]]
return observation, reward, done| 반환값 | 설명 |
|---|---|
observation |
이동 후 좌표 |
reward |
보상 값 |
done |
종료 여부 (True: 도착지점 도달 or 미로 밖 이동) |
📌 이 반환 형식은 OpenAI의 Gym 라이브러리와 동일한 구조로, 학습 환경 구현에 익숙한 형식이다.
🚶 Agent 클래스 정의
class Agent:
# 1. 행동에 따른 에이전트의 좌표 이동(위, 오른쪽, 아래, 왼쪽)
action = np.array([[-1,0], [0,1], [1,0], [0,-1]])
# 2. 각 행동별 선택 확률
select_action_pr = np.array([0.25, 0.25, 0.25, 0.25])
# 3. 에이전트의 초기 위치 설정
def __init__(self, initial_position):
self.pos = initial_position
# 4. 에이전트의 위치 저장
def set_pos(self, position):
self.pos = position
return self.pos
# 5. 에이전트의 위치 불러오기
def get_pos(self):
return self.pos- 각 행동은
[x, y]좌표 변화량으로 구성 - 예: 현재
[0,0]에서 오른쪽(action[1] = [0,1])을 선택하면 →[0,1]로 이동 - 모든 행동의 선택 확률은 균등(25%)
✅ 요약
| 구성 요소 | 설명 |
|---|---|
Environment |
미로 구조 및 보상 설계, 이동 처리 |
Agent |
위치, 행동 정의 및 이동 제어 |
move() |
행동 실행 결과 반환 (좌표, 보상, 종료 여부) |
'독서 > 기초부터 시작하는 강화학습 신경망 알고리즘' 카테고리의 다른 글
| 4.1 정책 평가와 반복 정책 평가 (0) | 2025.03.31 |
|---|---|
| 3.2 가치함수: 행동 가치 계산 (0) | 2025.03.31 |
| 3.1 가치함수: 상태 가치 계산 (0) | 2025.03.29 |
| 2. 강화학습의 기본 요소 (1) | 2025.03.28 |
| 1. 인공지능이란? (0) | 2025.03.28 |